3 Building a UK local news directory
In this chapter, I do two things:
put together all existing data sources for local news titles in the UK and build a huge (and, I admit, messy) UK local and regional news directory. The directory attempts to be capture “official” titles as well as established hyperlocals. To get there, I follow similar sources (e.g., JICREG, ABC, LMW) to previous studies, but differently from all of them I: a) automate the data extraction where possible, to keep the data as current as possible; b) merge all possible trusted sources, instead of relying on a single one or a few (I use regulators, media owners lists, associations lists, circulation auditors, and more).
create my own directory which ultimately relies on the best source out of all them (hint: it’s Media Coalition Reform latest available dataset from 2021), and simply updates with the latest newspaper closures and launches as reported by the Press Gazette. The goal of this directory is to become the basis and starting point for my PhD research, guiding me in selecting a suitable sample of local papers to study in my project on the geographical relevance of local news content.
Truth be said, I was hoping to be able to perform a data verification and cleaning in the automation merging (my messy dataset) that would lead me to an original and clean directory, however I encountered big challenges in merging and cleaning the data (for example differences in how newspapers or their owners are called across different sources, or not entirely trusting one source). So that lead me to ultimately build my own directory from the one cleanest and most updated source I found. Nonetheless, I think my automation efforts can still be useful to keep track of changes on listings across different sources, and let anyone be able to see these changes overtime (and if anyone wants to clean my dataset, please be my guest!).
3.1 General challenges
Putting together a directory is not really straightforward in the UK. For one, due to the lack of a dataset existing solely with the purpose of mapping the number of local titles in the country, without any further specification or limitations such as that they should be hyperlocals, or should be recorded by JICREG.
As Ramsay and Moore explained in 2016 (p.18):
Establishing the exact number of distinct local newspapers available in the UK proved to be a difficult and time-consuming process, due to deficiencies in existing publicly available databases. These databases miss out a number of newspapers, and in many cases contain only grouped or aggregate information for a number of titles covering different local areas. For this analysis, a new and comprehensive list of individual local newspaper titles, including distinct sub-editions, was generated, using a variety of information sources.
And (p.19):
Gaps in existing datasets are in part due to the large number of titles, and relatively regular ‘churn’ of the figures due to closures, mergers and the creation of new titles. However, some of the sources of data – including the brand lists provided publicly or on request by some publishing groups – are (at the time of writing) out-of-date, and some combine multiple individual and distinct titles into single grouped cases. In order to compile as comprehensive a list of local titles as possible, this report used numerous different data sources and, where necessary, newspapers and news groups were contacted directly. Given the discrepancies between the sources, the number of newspapers involved, and the regularity with which newspapers change hands, merge or close, it must be borne in mind that a small number of titles may have escaped inclusion.
3.2 The big dataset
Below, I parse data from around 17 differnt sources, which, for easiness, I have grouped in: regulators, membership association sites, publishers, and other.
3.2.1 Regulators
After the Leveson Inquiry the Press Recognition Panel (PRP) was set up under the Royal Charter on self-regulation of the press to judge whether press regulators meet the criteria recommended by the Inquiry. By 2016 two new press regulatory bodies were set up in the UK: the Independent Press Standards Organisation (IPSO), which regulates most national newspapers and many other media outlets, and IMPRESS, which regulates a much smaller number of outlets but is the only press regulator recognised by the PRP.
IPSO
The Independent Press Standards Organisation (IPSO) is the independent regulator for the newspaper and magazine industry in the UK. It was created in 2014 following the windup of the Press Complaints Commission (PCC), which had existed since 1990. IPSO monitors and regulates newspapers and magazines, overseeing their actions, upholding high standards of journalism and helping to maintain freedom of expression for the press. Several broadsheet newspapers (e.g., The Guardian and The Financial Times) have declined to join IPSO, establishing their own independent complaints systems. IPSO regulates more than 1,500 print titles and more than 1,100 online titles, including most of the UK’s national newspapers. IPSO is funded by its member publishers. IPSO has not sought recognition under the Royal Charter.
# generate urls
suffices <- c("0,1,2,3,4,5,6,7,8,9", letters)
urls <- paste0("https://www.ipso.co.uk/complain/who-ipso-regulates/?letters=", suffices)
# define the scraping function
scraper <- function(urls) {
read_html(urls) %>%
html_elements(".pagination-listings") %>%
html_elements("li") %>%
html_text() %>%
as.data.frame()
}
# iterate over the urls
ipso <- map_dfr(urls, scraper)
ipso <- ipso %>%
mutate(
Publisher = str_extract(., "\\s\\([^)]+\\)$"),
Publisher = str_remove(Publisher, "\\("),
Publisher = str_remove(Publisher, "\\)"),
Publication = str_remove(., "\\s\\([^)]+\\)$"),
Publisher = str_remove(Publisher, "\\s$")) %>%
select(-.) %>%
mutate_all(str_trim) %>%
mutate(retrieval_date = Sys.Date())
ipso_len <- dim(ipso)[1]
# processing publishers: how many are there, and who are the biggest ones?
ipso_publishers <- ipso %>%
count(Publisher) %>%
arrange(desc(n)) %>%
mutate(perc = round(n/nrow(ipso)*100,2)) %>%
na.omit()
ipso_publishers_tot <- nrow(ipso_publishers)Ipso regulates 2103 titles. These belong to 99 different publishers. Here below are shown the 10 predominant ones.
kable(ipso_publishers[1:10, ])| Publisher | n | perc |
|---|---|---|
| Newsquest Media Group | 461 | 21.92 |
| National World Publishing Ltd | 348 | 16.55 |
| Reach PLC | 251 | 11.94 |
| Future PLC | 165 | 7.85 |
| Tindle Newspapers Limited | 93 | 4.42 |
| Immediate Media Company Limited | 86 | 4.09 |
| H. Bauer Publishing | 83 | 3.95 |
| DC Thomson Group | 76 | 3.61 |
| Iliffe Media Group Ltd | 54 | 2.57 |
| Nub News Ltd | 49 | 2.33 |
# append to ipso file
ipso_main <- read_csv("./files/ipso.csv")
ipso <- ipso_main %>% bind_rows(ipso) %>% group_by(Publication, Publisher) %>% arrange(retrieval_date) %>% slice(1L)
write_csv(ipso, "./files/ipso.csv")Impress
IMPRESS stands for the Independent Monitor for the Press. The company’s aim revolves around helping to build understanding and trust between journalists and the public. Like IPSO, they operate as press regulators, maintaining a Standards Code and assessing any breaches of this code by their members.
url <- "https://www.impress.press/regulated-publications/"# url
# define the scraping function
scraper_impress <- function(url) {
read_html(url) %>%
html_elements(".span-md-8") %>%
html_elements("a") %>%
html_text()
}
# iterate over the urls
impress_members <- as.data.frame(scraper_impress(url)) %>%
rename("Publication" = "scraper_impress(url)") %>%
mutate(Type = case_when(
str_detect(Publication, "online") ~ "Online",
str_detect(Publication, "print") ~ "Print",
TRUE ~ "Unknown"
))
# now let's get the social media handles and urls
social_media <- read_html(url) %>%
html_elements(".span-md-8") %>%
html_elements("a") %>%
html_attr("href")
impress_sm_scraper <- function(page) {
doc <- read_html(url(page))
list(
Publication <- doc %>% html_element("h1") %>% html_text() %>% str_remove(".*\\| "),
twitter_url <-
doc %>% html_elements(xpath = "//p/a[contains(@href, 'twitter.com/')]/@href") %>% html_text(),
twitter_handle <-
doc %>% html_elements(xpath = "//p/a[contains(@href, 'twitter.com/')]/text()") %>% html_text(),
facebook_handle <-
doc %>% html_elements(xpath = "//a[contains(@href, 'facebook.com/')]/@href") %>% html_text()
)
}
table <- lapply(social_media, impress_sm_scraper)
dt_list <- map(table, as.data.table)
dt <- rbindlist(dt_list, fill = TRUE, idcol = T) %>% group_by(.id) %>% slice_tail(n = 1)
impress <- impress_members %>% rowid_to_column() %>% full_join(dt, by = c("rowid" = ".id")) %>%
select(-V1) %>%
rename("Twitter handle" = V3,
"Twitter url" = V2,
"Facebook url" = V4) %>%
mutate(Publication = gsub("\\s+\\(print.*|\\s+\\(onl.*", "", Publication)
) %>%
group_by(Publication) %>%
summarise(
across(everything(), # apply to all columns
~paste0(unique(na.omit(.x)), collapse = "; "))) %>% # function is defined which combines unique non-NA values
mutate(retrieval_date = Sys.Date())
# append to impress file
#write_csv(impress, "./files/impress.csv") #if running the code for the first time
impress_main <- read_csv("./files/impress.csv")
impress <- impress_main %>% bind_rows(impress) %>% group_by(Publication) %>% arrange(retrieval_date) %>% slice(1L)
write_csv(impress, "./files/impress.csv")3.2.2 Membership Associations and Circulation Compilers
HoldtheFrontPage
HoldtheFrontPage (HTFP) is a news website focusing on UK regional media, whose audience is journalists and journalism students. They publish articles that highlight battles, efforts, and achievements of local and regional newspapers. HoldtheFrontPage.co.uk Limited is independently-owned and is a member of the Independent Community News Network and the Independent Press Standards Organisation.
HoldtheFrontPage maintains a directory of UK regional and local newspapers, newspaper websites, newspaper publishing companies and the people who work for them. The directory is organised in separate pages, grouping titles by typology: Websites, Daily Newspapers, Weekly Newspapers, and Hyperlocals. There are also Media Companies and Freelancers, which are left out of this analysis as not relevant to my directory.
# generate urls
root_url <- "https://www.holdthefrontpage.co.uk/directory/"
suffices <- c("newspaperwebsites/",
"dailynewspapers/",
"weeklynewspapers/")
urls <- paste0(root_url,
suffices)
# define scraping function
pager <- function(page) {
doc <- read_html(url(page))
data.frame(
Publication = doc %>% html_elements(".pf-content") %>%
html_elements("li") %>%
html_text(),
Website = doc %>% html_elements(".pf-content") %>%
html_elements("li") %>% html_element("a") %>%
html_attr("href"),
Type = doc %>% html_elements(".entry-title") %>%
html_text()
)
}
htfp <- do.call(rbind, lapply(urls, pager))
htfp[1:76, 3] <- "Online daily"
htfp[77:866, 3] <- "Online weekly"
# I am doing hyperlocals separately from the rest as the web structure is different
hyperlocals <-
"https://www.holdthefrontpage.co.uk/directory/hyperlocal-publications/"
hl <-
data.frame(
Publication <-
read_html(hyperlocals) %>% html_elements("td:nth-child(1)") %>%
html_text(),
Website <-
read_html(hyperlocals) %>% html_elements("td:nth-child(2)") %>%
html_element("a") %>% html_attr("href"),
Type <- "Hyperlocal publications"
)
names(hl) <- c("Publication", "Website", "Type")
hl <- hl[-c(1:2), ]
# put it all together
htfp_database <- rbind(htfp, hl) %>%
mutate(Notes = as.character(str_extract(Publication, "\\(.*|\\,.*")),
Notes = str_remove_all(Notes, "\\)|\\(|\\, "),
Publication = str_remove_all(Publication, " \\(.*|\\,.*"),
Publication = str_remove(Publication, "\\s$")) %>%
mutate(Type = case_when(Type == "Regional Weekly Newspapers in the UK" ~ "Weekly",
Type == "Regional Daily Newspapers in the UK" ~ "Daily",
Type == "Online daily" ~ " Online Daily",
Type == "Online weekly" ~ "Online Weekly",
TRUE ~ as.character(Type))) %>%
group_by(Publication) %>%
summarise(across(everything(), ~paste0(unique(na.omit(.x)), collapse = "; "))) %>% # combine unique non-NA values
mutate(retrieval_date = Sys.Date())
HTFP_len <- nrow(htfp_database)
total_titles <- nrow(htfp) + nrow(hl)
print <- htfp_database %>%
filter(Type %in% c("Weekly", "Daily")) %>%
nrow()
online_only <- htfp_database %>%
filter(Type %in% c("Online Daily", "Online Weekly")) %>%
nrow()
hyperlocals <- nrow(hl)
online <- HTFP_len - print - hyperlocals
online_and_print <- online - online_only
non_hyperlocals <- HTFP_len - hyperlocals
dailies <- htfp_database %>%
filter(str_detect(Type, 'Daily')) %>%
nrow()
weeklies <- htfp_database %>%
filter(str_detect(Type, 'Weekly')) %>%
nrow()
# append to htfp_database file
#write_csv(htfp_database, "./files/htfp.csv") #if running the code for the first time
htfp_main <- read_csv("./files/htfp.csv")
htfp <- htfp_main %>% bind_rows(htfp) %>% group_by(Publication) %>% arrange(retrieval_date) %>% slice(1L)
write_csv(htfp, "./files/htfp.csv")On HTFP’s site, there are currently 1347 unique titles listed. Oftentimes, titles have both a print and an online edition. When counting them separately, we find 1749 titles. The table below summarises what the HTFP directory includes, updated to 2023-02-02.
kable(data.frame(c("Online", "Online only", "Online and print", "Print only", "Dailies", "Weeklies", "Unique titles"), c(hyperlocals, "unknown", "unknown", 0, "unknown", "unknown", hyperlocals), c(online, online_only, online_and_print, print, dailies, weeklies, non_hyperlocals)), col.names = c("Variable","Hyperlocals", "Legacy Media"))| Variable | Hyperlocals | Legacy Media |
|---|---|---|
| Online | 116 | 861 |
| Online only | unknown | 436 |
| Online and print | unknown | 425 |
| Print only | 0 | 370 |
| Dailies | unknown | 111 |
| Weeklies | unknown | 1127 |
| Unique titles | 116 | 1231 |
JICREG
JICREG (Joint industry Currency for Regional Media Research) is the trading currency for local media in Great Britain. It has representation on the board and technical committee from advertisers, agencies and publishers, guaranteeing its objectivity as a trusted and transparent audience measurement system.
Launched in 1990, JICREG provides free and paid subscribers access to its monthly updated data. The platform, JICREG Online, is capable of generating over 100,000 reports. JICREG is used both by media companies and communication brands to help understand audience circulation.
As of 05/10/2022 there are 520 local daily and weekly newsbrands reported within the JICREG database, which include 71 daily titles and 449 weekly titles covering Great Britain (Northern Ireland is excluded). To be included on JICREG the print title must:
have an audited circulation figure, ABC is the preferred auditor although other auditors are accepted if they comply with JICREG audit guidelines;
be published at least weekly and also be a member of the News Media Association and listed within the Local Media Works database.
Automating data extraction from JICREG is no easy task. The page is behind login and most useful features behind a paid subscription which I do not have. Within the free account, there is no option to obtain the full dataset at once and scraping seems tricky because of the embedded Javascript on the page (e.g. URL is not customisable, so I would have to use Selenium and type the name of each location I want to search: so 380 LADs). For this reason, I have done the only available alternative, which is to head over to Historical Records within the JICREG website and download as pdf the latest release of circulation figures (October 2021) for all newspapers in their database. I have converted the pdf to csv.
jicreg <- read.csv("./files/JICREG_2020.csv") %>% mutate(Scope = "Local")Local Media Works
The Local Media Works Database is a database of newsbrands maintained by Local Media Works, part of the News Media Association (NMA) – a representative group set up by the national, regional and local newspaper industry to promote their interests. This is closely linked – but not identical – to the Joint Industry Committee for Regional Media Research (JICREG) database. The NMA promotes the interests of news media publishers to Government, regulatory authorities, industry bodies and other organisations whose work affects the industry.
The database can be searched by geographic location or newspaper name, although the geographic unit is not specified. One cannot extract the full dataset. Otherwise one can look at a page featuring the list of newsbrands which supposedly should make their database, but in this case circulation information is not featured.
Regarding the database, their website states:
The LMW Database provides the most up-to-date and detailed information available on UK local news brands across the UK including audited circulation breakdowns, web traffic data and other data on local newspapers and their companion websites. Data for each newspaper, website and other platform includes address and contact information, type, frequency, circulation and readership information, both total and by area, advertising rates, format, and publishing day.
The page mentions JICREG (and I suppose the circulation figures they report originate indeed from JICREG). Regarding JICREG, LMW states:
The JICREG database provides detailed newspaper readership and website audience data for local newsbrands in the UK. The gateway to this data is JICREG Online which enables advertisers, marketers and campaigners to target tightly defined audiences. In 2021, JICREG Life is Local was launched by Local Media Works for the JICREG database update.
# It says on the JICREG website that is should match Local Media Works directory. Let's check.
url <- "https://newsmediauk.org/local-media-works/a-z-newsbrands/"
lmw <- read_html(url)
lmw <- data.frame(
Publication = lmw %>% html_elements(".az-newsbrand") %>%
html_elements("a") %>%
html_text(),
Website = lmw %>%
html_elements(".az-newsbrand") %>%
html_elements("a") %>%
html_attr("href"),
Scope = "Local",
retrieval_date = Sys.Date()
)
# titles in lmw not in jicreg
l_not_j <- anti_join(lmw, jicreg, by= "Publication")
# append to lmw file
#write_csv(lmw, "./files/lmw.csv") #if running the code for the first time
lmw_main <- read_csv("./files/lmw.csv")
lmw <- lmw_main %>% bind_rows(lmw) %>% group_by(Publication) %>% arrange(retrieval_date) %>% slice(1L)
write_csv(lmw, "./files/lmw.csv")ABC
ABC circulation data is unfortunately hard to automatically retrieve. Thus I extracted the data in December 2022 manually. The good thing is that the data is updated yearly or twice a year at regular dates, reducing the need for automation.
abc <- read_csv("./files/abc.csv")3.2.3 Publishers
Inspired by Moore and Ramsay, I decided the picture would finally be complete if I added an extraction of the titles from each major media company here. Following the list found in Ramsay and Moore, and cross-checking it with Hold the Front Page (more updated) I enlisted these companies to scrape:
1. Reach PLC
2. Newsquest (includes the former Archant)
3. Illiffe - websites and papers
4. Tindle
5. DC Thomson
6. MNA
From the perspective of the main UK regional publishers, one is missing from this parsing effort: National World (before april 2022 called JPIMedia and before 2018 Johnston Press). On the site (and elsewhere online) I cannot find a list of their brands.
reach <- read_html("https://en.wikipedia.org/wiki/List_of_Reach_plc_titles") %>%
html_elements(xpath = "//div[@id='mw-content-text']/div[1]/ul[2]/li") %>%
html_text() %>%
as.data.frame() %>%
rename(Publication = 1) %>%
mutate(retrieval_date = Sys.Date())
# append to file
#write_csv(reach, "./files/reach.csv") #if running the code for the first time
reach_main <- read_csv("./files/reach.csv")
reach <- reach_main %>% bind_rows(reach) %>% group_by(Publication) %>% arrange(retrieval_date) %>% slice(1L)
write_csv(reach, "./files/reach.csv")newsquest <- read_html("https://www.newsquest.co.uk/news-brands") %>%
html_elements(xpath = '//div[@class="modal-scroll grid"]//p[@class="divider"][1]') %>% html_text() %>% trimws() %>% str_split_fixed("\\s+\\s+", 5) %>% as.data.frame() %>% mutate(retrieval_date = Sys.Date())
newsquest$V5 <- str_remove(newsquest$V5, "London\\s+\\s+")
colnames(newsquest) <- c("Publication", "Address1", "Address2", "County", "Postcode", "retrieval_date")
# save
#write_csv(newsquest, "./files/newsquest.csv") #if running the code for the first time
newsquest_main <- read_csv("./files/newsquest.csv")
newsquest <- newsquest_main %>% bind_rows(newsquest) %>% group_by(Publication) %>% arrange(retrieval_date) %>% slice(1L)
write_csv(newsquest, "./files/newsquest.csv")url <- c("https://www.iliffemedia.co.uk/portfolio/online/", "https://www.iliffemedia.co.uk/portfolio/publications/")
scraper <- function(x) {
read_html(x) %>%
html_elements(xpath = "//option[@value]") %>% html_text() %>% trimws()
}
illiffe <- lapply(url, scraper)
illiffe <- map(illiffe, as.data.frame)
illiffe <- rbindlist(illiffe) %>% filter(!row_number() %in% 1)
colnames(illiffe) <- "Publication"
illiffe$retrieval_date <- Sys.Date()
# save
write_csv(illiffe, "./files/illiffe.csv") #if running the code for the first time
illiffe_main <- read_csv("./files/illiffe.csv")
illiffe <- illiffe_main %>% bind_rows(illiffe) %>% group_by(Publication) %>% arrange(retrieval_date) %>% slice(1L)
write_csv(illiffe, "./files/illiffe.csv")tindle <- read_html("https://tindlenews.co.uk/portfolio") %>%
html_elements("#newsitems") %>%
html_elements("a") %>%
html_attr("href")
scraper <- function (x) {
doc <- read_html(x)
data.frame(
Publication <- doc %>% html_elements(".wrap .row") %>% html_element("h1") %>% html_text() %>% na.omit(),
Address <- doc %>% html_elements(".m-0") %>% html_element("p") %>% html_text() %>% extract2(1)
)
}
tindle <- rbindlist(lapply(tindle, scraper))
colnames(tindle) <- c("Publication", "Address")
tindle$retrieval_date <- Sys.Date()
# save
#write_csv(tindle, "./files/tindle.csv") #if running the code for the first time
tindle_main <- read_csv("./files/tindle.csv")
tindle <- tindle_main %>% bind_rows(tindle) %>% group_by(Publication) %>% arrange(retrieval_date) %>% slice(1L)
write_csv(tindle, "./files/tindle.csv")#DC Thomson brands list feels quite irrelevant. Most are magazines or trade publications. The news publications include Press and Journal, Evening Express, and The Sunday Post, which arguably are too large scale to be considered local.
dc <- read_html("https://www.dcthomson.co.uk/brands/") %>%
html_elements(".overflow .block") %>%
html_attr("href")
scraper <- function (x) {
doc <- read_html(x)
list(
Publication <- doc %>% html_elements("h1") %>% html_text(),
Twitter <- doc %>% html_elements(".twitter-social-link") %>% html_attr("href"),
Address <- doc %>% html_elements(".address") %>% html_text()
)
}
dc1 <- rbindlist(lapply(dc, scraper)) %>% na.omit()
colnames(dc1) <- c("Publication", "Twitter", "Address")
dc1$retrieval_date <- Sys.Date()
# save
#write_csv(dc1, "./files/dc_thomson.csv") #if running the code for the first time
dc_thomson_main <- read_csv("./files/dc_thomson.csv")
dc_thomson <- dc_thomson_main %>% bind_rows(dc1) %>% group_by(Publication) %>% arrange(retrieval_date) %>% slice(1L)
write_csv(dc_thomson, "./files/dc_thomson.csv")mna2 <- read_html("https://www.mnamedia.co.uk/news-titles/") %>% html_elements(".full_size h3") %>% html_text() %>% as.data.frame() %>% rename("Publication" = 1) %>% filter(!str_detect(Publication, "WEEKLY|DAILY|MONTHLY"))
mna <-
read_html("https://www.mnamedia.co.uk/news-titles/") %>% html_elements(xpath = "//body/div/div/div/main/div/div/div/div/div/div/div/div/div/div/div/div/div/div/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div[1]/div") %>% html_text() %>% trimws() %>% as.data.frame() %>% filter(!row_number() %in% c(1, 2)) %>% rename("Description" = 1) %>% mutate(Frequency = substr(Description, 1, 1)) %>% mutate(
Description = str_remove(Description, "WEEKLY|DAILY|MONTHLY"),
Description = str_replace_all(Description,
pattern = "([[:upper:]])",
replacement = " \\1"),
Description = str_replace_all(Description, " ", " ")
) %>% fuzzy_left_join(mna2,
by = c("Description" = "Publication"),
match_fun = str_detect) %>%
mutate(retrieval_date = Sys.Date())
# save
#write_csv(mna, "./files/mna.csv") #if running the code for the first time
mna_main <- read_csv("./files/mna.csv")
mna <- mna_main %>% bind_rows(mna) %>% group_by(Publication) %>% arrange(retrieval_date) %>% slice(1L)
write_csv(mna, "./files/mna.csv")3.2.4 Hyperlocals, Ramsay & Moore, Media Coalition Reform
Community journalism hyperlocals The Independent Community News Network (ICNN) is a network of hyperlocal that exists to support independent titles and publishers and to promote quality journalism, in their words, to help address the democratic deficit in news poor communities and help create more jobs at the local level.
From their website: “Of these 100+ members, nearly half have either complimentary print newspapers, or publish a weekly, fortnightly, or monthly newspaper exclusively. Membership is most concentrated in London, Bristol, Cardiff, and Manchester. The 15+ titles that cover the city of Bristol and the surrounding area are exclusively print publications. However, many of these belong to the same publisher. The south coast appears to be fertile ground for independent community news, as does the east midlands. Anglia, including Cambridge, Bedfordshire, and Hertfordshire are vastly under-represented in terms of represented independent news coverage. This is compounded by the lack of legacy media in these areas too. The same can be said for Yorkshire and the North East. This is not to say that there is no coverage in these areas at all. This map indexes titles represented by ICNN only. Our most recent members, as of September 2020, are North Edinburgh Community News (affectionately called The Ems), Altrincham Today, and the Mansfield, Ashfield and Warsop News Journal.”
patterns_cj <-
c("(?<=.com).*", "(?<=.co.uk).*", "(?<=.org).*") # cleaning urls for matching
remove <- c("PointZ\\s\\(", "\\s\\d\\)")
# dataset I extracted from interactive map (contains old members that were not shown in map but included in the javascrip map file)
cj <- read_csv("./files/ICNN.csv") %>%
mutate(
Coordinates = str_remove_all(Coordinates, paste(remove, collapse = "|")),
Website = str_remove(Website, pattern = paste(patterns_cj, collapse = "|"))
) %>% na.omit()
# dataset I extrscted from member page (does not contain geographic info, but the list seems more updated, thus I will merge this with the above)
# sometimes matches are good at the Publication level, sometimes at the Website level. To maximise both, I am making two joins and then coalescing on the two resulting dfs
cj2 <-
read_delim("./files/icnn_members_feb23.csv",
col_names = FALSE,
delim = ";") %>%
na.omit() %>% left_join(cj,
by = c("X1" = "Publication")) # matching on Publication
patterns_cj2 <-
c("(?<=.com).*",
"(?<=.co.uk).*",
"(?<=.org).*",
"(?:.(?!\\/))+$") # cleaning urls for matching
cj3 <-
read_delim("./files/icnn_members_feb23.csv",
col_names = FALSE,
delim = ";") %>%
na.omit() %>% mutate(X2 = str_remove(X2, pattern = paste(patterns_cj2, collapse = "|"))) %>% left_join(cj,
by = c("X2" = "Website")) # matching on Website
# coalescing the 2: the resulting cleaned dataframe. There are a few observations missing coordinates, as they were on the members page but not the other
cj4 <- inner_join(cj2, cj3, by = "X1") %>%
mutate(
Coordinates = coalesce(Coordinates.x, Coordinates.y),
Website = coalesce(X2.y, Website),
Publication = coalesce(X1, Publication)
) %>%
select(Publication, Website, Coordinates) %>%
distinct(Publication, .keep_all = TRUE)
# there is another (seemed more powerful) way I could have done this, using sqldbf, but I was not familiar with the sql syntax so I went all dplyr insteadRamsay and Moore
I reached out to Dr Gordon Ramsay (author of many of the consulting work, as well as Monopolising the News), in relation to accessing the data behind local news mapping. He supplied me with his dataset of the time. Although much of this info is outdated, I can extract some useful info for those outlets still in existence (e.g., geographical location).
ramsay <- read_csv("./files/Ramsay.csv")Media Coalition Reform 2021
Brilliant dataset published online and created for the Who Owns the UK Media 2021 report. However, the methodology followed to put it together is unknown.
mrc2021 <- read_csv("./files/MRC_2021.csv") %>%
filter(!`2021 owner` %in% c("CLOSED", "CLOSED/INCORPORATED")) %>% # filter out closures
rename("Publication" = Title)3.2.5 Merging
# keep only each unique dataset
rm(list=ls()[! ls() %in% c("ipso","htfp_database", "impress", "jicreg", "lmw", "abc", "reach", "newsquest", "illiffe", "tindle", "dc1", "mna", "media_info", "cj4", "mrc2021", "ramsay")])
merger <- function(x) {
x <- x %>% select(Publication)
}
dfs <- Filter(function(x) is(x, "data.frame"), mget(ls()))
dfs <- lapply(dfs, merger)
merged <- bind_rows(dfs, .id = "id")
saveRDS(merged, "merged.rds") # saving the 7899 row objectFirst operation is cleaning duplicates that exist across datasets. My total list at present includes 7899 titles, which surely include many duplicates. In fact, considered I am merging 15 files, if a title appeared in all 15 datasets I would be counting it 15 times.
# keep only each unique dataset
rm(list=ls()[! ls() %in% c("ipso","htfp_database", "impress", "jicreg", "lmw", "abc", "reach", "newsquest", "illiffe", "tindle", "dc1", "mna", "media_info", "cj4", "mrc2021", "ramsay")])
dfs <- Filter(function(x) is(x, "data.frame"), mget(ls()))
# make directory!
directory <- bind_rows(dfs, .id = "id") %>%
group_by(Publication) %>%
summarise(across(everything(), ~paste0(unique(na.omit(.x)), collapse = "; ")))
saveRDS(directory, "directory.RDS")
directory <- readRDS("directory.RDS") %>% mutate_all(~na_if(., ""))
count <- nrow(directory)My directory has, upon a full merge of my sources, 4419 titles. Surely most of them are undetected duplicates and many irrelevant publications (e.g. national titles), especially from directories such as ipso.
3.3 The directory
To be able to work with a smaller and cleaner dataset, I decided to not invest any further time in trying to clean my above huge dataset, and instead look at what I can do with the data at hand to have something that is better than anything already out there (e.g., more updated, more comprehensive).
Out of all my data sources, two impressed me: the Media Reform Coalition dataset and Ramsay’s old directory. The former for its “recentness” and the latter for its methodological robustness. Following this logic, I can rely on these two datasets solely, while the remainder datasets can be used for simply extracting further variables, or implementing gaps.
A quality statement of the consistency given by the two datasets (which surely is partly influenced by the fact that MRC’s mission had started with Ramsay - indicating consistency in spelling of titles and approach), can be seen in the figure below. Around 900 titles appear in both Ramsay’s and MRC’s datasets, which considered they have respectively 1106 and 1021 titles, makes these two datasets an ideal starting point for identifying titles in existence without too much data wrangling, and geographically mapping titles (since both present geographic data, at the postcode/city and LAD level respectively).
merged <- readRDS("merged.rds")
pairs <- merged %>%
group_by(Publication) %>%
reframe(pair = c(outer(sort(id),
sort(id), paste, sep = '-'))) %>%
ungroup %>%
count(pair, sort = TRUE, name = 'number_of_events')
p <- pairs %>%
separate(pair, "-", into = c("A", "B")) %>%
filter(A != B) %>%
unite("pair", A:B, sep = "-") %>%
distinct(number_of_events, .keep_all = TRUE) %>%
ggplot(aes(x = number_of_events, y = 0)) +
geom_jitter(
height = 0.25,
size = 4.5,
col = "lightslateblue",
fill = "lightslateblue",
alpha = 0.5
) +
scale_y_continuous(limits = c(-0.2, 0.2), breaks = c(0, 0)) +
xlab("co-occurrences") +
ylab("") +
theme_minimal() +
theme(axis.text.y = element_blank(),
axis.line.y = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank()) +
annotate(
geom = "text",
x = 800,
y = 0.05,
label = "Ramsay-MRC21",
hjust = "left"
)
p1 <- pairs %>%
separate(pair, "-", into = c("A", "B")) %>%
filter(A != B) %>%
unite("pair", A:B, sep = "-") %>%
distinct(number_of_events, .keep_all = TRUE) %>%
ggplot(aes(x=reorder(pair,-number_of_events), y = number_of_events)) +
geom_bar(stat = "identity", fill = "lightslateblue")+
coord_flip() +
xlab("pair") +
ylab("titles co-occurrences")+
theme_minimal()+
theme(panel.grid.minor.y = element_blank(),
panel.grid.major = element_blank(),
axis.text.y = element_text(size = 6.8))
jpgfile <- fs::path(knitr::fig_path(), "cooccurrences.jpeg")
ggsave(jpgfile, p1, width = 40, height = 30, units = "cm", scaling = 3)
knitr::include_graphics(jpgfile)
There are around 150 titles that do not appear in MRC but appear in Ramsay. I checked a few of those, and they were papers which shut down since Ramsay’s research. I can thus make the assumption that this applies to all of these titles, and reduce my main source to 1. Thus, if I used solely the MRC dataset as a starting point, what improvements could I make?
- check whether all 2021 closures and openings recorded by PressGazette have been included
- remove 2022 closures and insert 2022 launches as recorded by PressGazette
- Archant and JPIMedia have since changed names (update this)
- add hyperlocals by ICNN
By filtering out MRC and ICNN from the merged dataset created above, I will be able to retain additional information about MRC and ICNN titles where these titles were present in any of the other datasets.
3.3.1 Number of titles
I can improve the MRC dataset in terms of adding hyperlocals by ICNN and by updating it with closures and launches from PressGazette. Furthermore, I can expand information on social media handles for these outlets through extracting this information from a website called media.info.
pattern <- c("mrc","cj4")
directory_final <- directory %>%
filter(grepl(paste0(pattern, collapse = "|"), id)) %>%
mutate(Scope = if_else(Scope == "", "Local", Scope))Using PressGazette’s yearly article on print and digital newspaper launches and closures in the UK, I made sure the new and old titles would be respectively included or excluded in my directory. In total, there were 57 changes in 2021, including 10 closures and 47 launches, whereas in 2022 (up until July) there have been 10 closures and 8 launches.
pg <- read_csv("./files/PG_launches_closures_2020_2022.csv")
directory_final <- anti_join(directory_final, pg[pg$Event == "Closure",], by = "Publication") # removal of closures
directory_final <- full_join(directory_final, pg[pg$Event == "Launch",], by = c("Publication", "Publisher", "Frequency")) %>% select(-Event) %>% rename("Launch" = Date)
directory_size <- nrow(directory_final)Removing closures from my MRC + hyperlocals dataset and adding launches leads me to identifying 1179 local news titles in the UK - and I think, for now, that is the best I can do.
So what other conclusions can I draw from this directory building?
Different sources, different sizes. Extracting directly from the publishers leads me to smaller estimates compared to relying on my directory (with the exception of DC Thomson, whose site features several national magazines and trade papers). Why this is the case is not sure. It could be that titles appearing both online and in print are presented once on brands sites, and twice in my directory. Or it could be a lack of updating or showcasing on the brands sites.
I investigated Tindle, which is relatively small as a publisher and has a big disparity. What I noticed was that Tindle’s sites presents 24 titles, whereas my directory has 74. Of these 74 titles, many are contained and recognised as owned by Tindle by many other data sources beyond MRC, such as HTFP, ipso, Local Media Works, abc. However, there was a correlation between Tindle’s titles being branded on Tindle’s page, and that title featuring on the ABC website. This makes me think that what is missing from Tindle’s site are relatively small titles.
directory_publishers <- directory_final %>%
mutate(`2021 owner` = case_match(`2021 owner`,
"Archant"~"Newsquest PLC",
"JPI Media"~"National World",
"Reach Plc"~"Reach PLC",
.default = `2021 owner`),
`2021 owner` = if_else(is.na(`2021 owner`),Publisher,`2021 owner`)) %>%
count(`2021 owner`)
merged <- readRDS("merged.rds")
merged_publishers <- merged %>%
group_by(id) %>%
count %>% filter(id %in% c("dc1","illiffe","mna","newsquest","reach","tindle")) %>%
mutate(id = recode(id, dc1 = "DC Thomson & Company Limited", illiffe = "Iliffe Media", mna = "Midland News Association",
newsquest = "Newsquest PLC", reach = "Reach PLC", tindle = "Tindle Newspapers Ltd"))
publishers <- full_join(merged_publishers, directory_publishers, by = c("id" = "2021 owner")) %>%
rename("Brands member lists" = n.x) %>%
rename("MRC" = n.y) %>%
na.omit() %>%
pivot_longer(c(`Brands member lists`, MRC), names_to = "Source") %>%
ggplot(aes(x = reorder(id,-value), y = value, color = Source)) +
geom_point(alpha = 0.6, size = 4)+
xlab("")+
ylab("number of titles")+
coord_flip()+
theme_minimal()
jpgfile <- fs::path(knitr::fig_path(), "publishers.jpeg")
ggsave(jpgfile, publishers, width = 45, height = 12, units = "cm", scaling = 3)
knitr::include_graphics(jpgfile)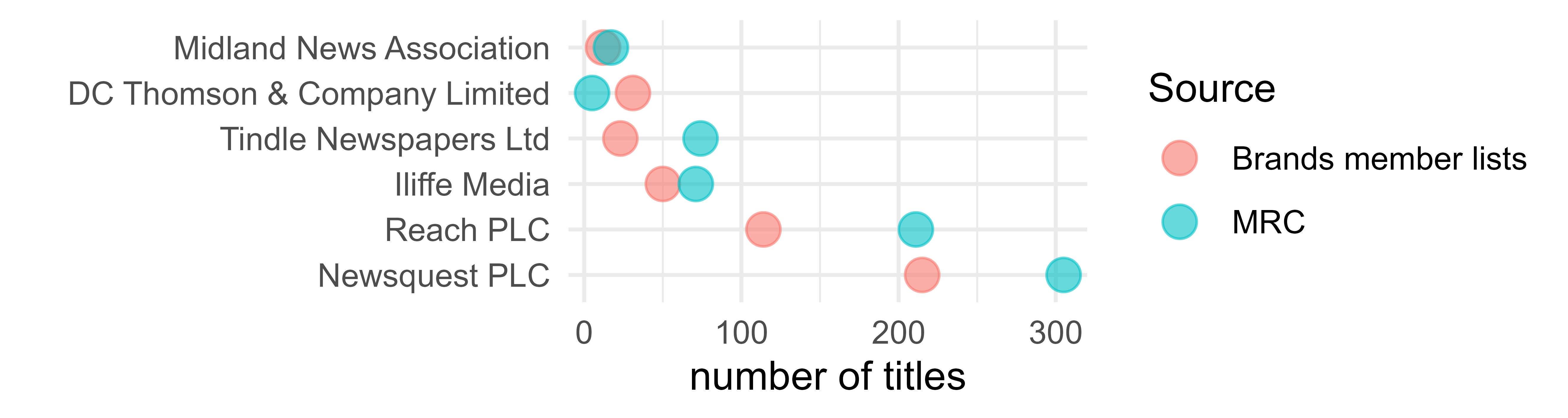
3.3.2 Ownership
Relying on data by Media Coalition Reform means having data that is built to understand ownership concentration. My directory takes the latest MRC dataset (2021) and applies relevant adjustments that reflect market acquisitions, closures and launches, rebranding efforts.
directory_final <- directory_final %>%
mutate(publisher_recoded = if_else(is.na(`2021 owner`),Publisher,`2021 owner`),
publisher_recoded = case_match(`2021 owner`,
"Archant"~"Newsquest PLC",
"JPI Media"~"National World",
"Reach Plc"~"Reach PLC",
"Reach"~"Reach PLC",
"Archant (now Newsquest)"~"Newsquest PLC",
.default = `2021 owner`)) %>%
select(-Publisher) %>%
relocate(Publication, publisher_recoded, id)
ownership <- directory_final %>%
group_by(publisher_recoded) %>%
count(sort = TRUE) %>%
filter(n > 5 & !is.na(publisher_recoded)) %>%
ggplot(aes(x = reorder(publisher_recoded, n), y = n)) +
geom_bar(stat = "identity", fill = "lightslateblue")+
coord_flip()+
theme_minimal()+
ylab("Number of titles") +
xlab("") +
scale_y_continuous(breaks = seq(0,450,25))+
theme(panel.grid.minor = element_blank(),
panel.grid.major.y = element_blank(),
axis.text.y = element_text(size = 10))+
labs(caption = "Filtered by publishers with a minimum of 5 titles.\nNA here indicates independent publishers from the hyperlocal dataset")
jpgfile <- fs::path(knitr::fig_path(), "ownership.jpeg")
ggsave(jpgfile, ownership, width = 60, height = 20, units = "cm", scaling = 3)
knitr::include_graphics(jpgfile)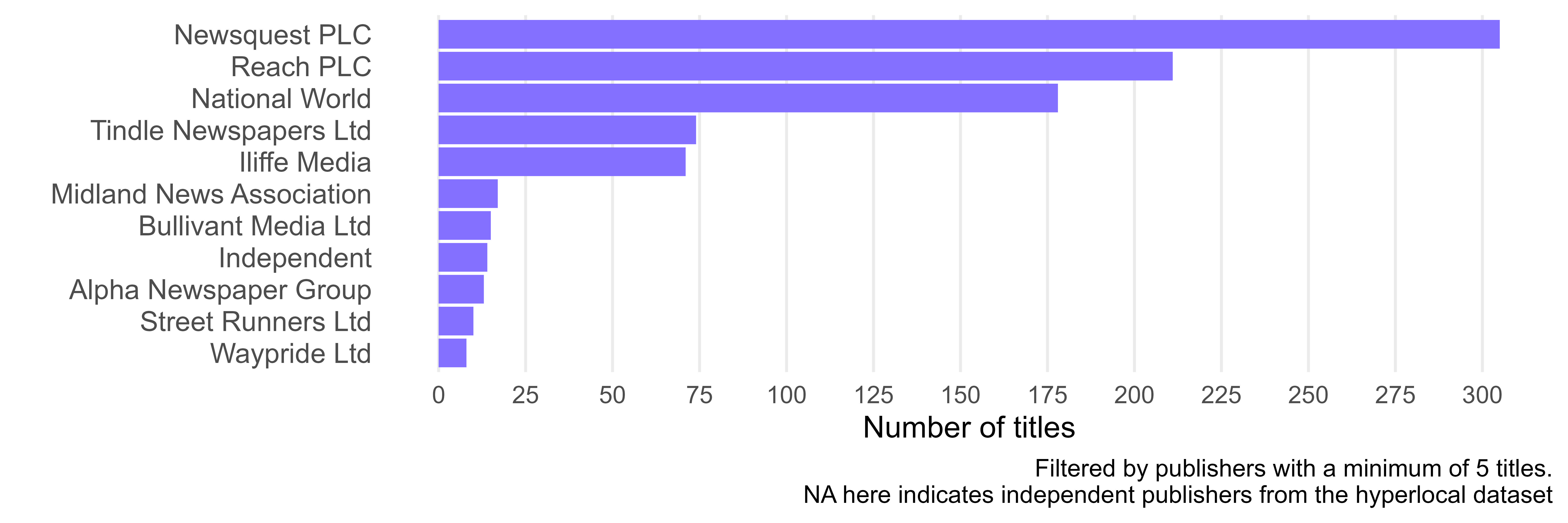
table_ownership <- directory_final %>%
group_by(publisher_recoded) %>%
count(sort = TRUE) %>%
ungroup() %>%
mutate(perc = round(n/sum(n, na.rm = TRUE)*100,2)) %>%
filter(n > 10)
kable(table_ownership, col.names = c("Owner", "Count", "%"))| Owner | Count | % |
|---|---|---|
| Newsquest PLC | 305 | 25.87 |
| Reach PLC | 211 | 17.90 |
| National World | 178 | 15.10 |
| NA | 169 | 14.33 |
| Tindle Newspapers Ltd | 74 | 6.28 |
| Iliffe Media | 71 | 6.02 |
| Midland News Association | 17 | 1.44 |
| Bullivant Media Ltd | 15 | 1.27 |
| Independent | 14 | 1.19 |
| Alpha Newspaper Group | 13 | 1.10 |
3.3.3 Frequency
The vast majority of titles appear to be weeklies. There are only 80 known dailies, against 869 weeklies. Knowing there are several hundres LADs in the UK, this resonates with previous findings that showed that many LADs lack a daily title.
frequency <- directory_final %>%
select(Publication, publisher_recoded, Frequency) %>%
mutate(Frequency = recode(na_if(Frequency, ""), .missing = "unknown")) %>%
mutate(Frequency = str_to_lower(Frequency)) %>%
count(Frequency, sort = TRUE) %>%
ggplot(aes(x = reorder(Frequency,n), y = n)) +
geom_bar(stat="identity", fill = "lightslateblue")+
xlab("Frequency")+
ylab("Number of titles")+
scale_y_continuous(breaks = seq(0,900, 50))+
coord_flip()+
theme_minimal()+
theme(panel.grid.minor = element_blank(),
panel.grid.major.y = element_blank(),
axis.text.y = element_text(size = 10))
jpgfile <- fs::path(knitr::fig_path(), "frequency.jpeg")
ggsave(jpgfile, frequency, width = 60, height = 14, units = "cm", scaling = 3)
knitr::include_graphics(jpgfile)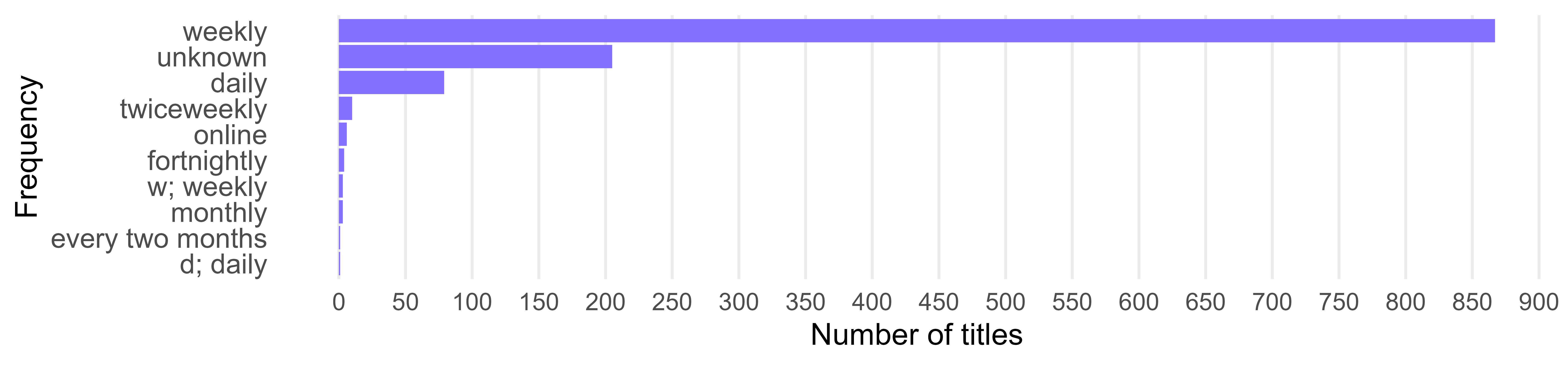
3.3.4 Hyperlocals
How many are hyperlocals or independent publishers?
h <- nrow(filter(directory_final, str_detect(id, "cj4") | publisher_recoded == "Independent"))The ICNN dataset includes solely hyperlocals. Instead, PressGazette includes independent publishers, and in one instance a publisher is included as independent in PG and features also in the ICNN site (probably because lines are blurry in terms of definitions, and while all hyperlocals are probably independent, not all independent publishers are hyperlocals. Between the two of them, I find 116 titles.
3.3.5 Twitter
While I am at it, I also extract Twitter information from a website called Media.info, which gathers data on media companies in the UK, including newspapers of all sizes and scopes, as well as magazine and TV. In this section I gather data from their newspaper directory to extract Twitter handles.
# TWITTER
remove <- c(".*\\d\\.\\s+", "\\s+-.*", "\\s+\\(.*")
mi_twitter <- read_html("https://media.info/uk/newspapers/data/twitter/titles") %>%
html_elements(".data") %>% html_table() %>% as.data.frame() %>%
mutate(Twitter = str_extract(X1, "@.*")) %>% mutate(Publication = str_remove_all(X1, paste(remove, collapse = "|"))) %>%
select(-c(X1,X2)) %>% na.omit()
directory_final <- directory_final %>% fuzzy_left_join(mi_twitter, by = "Publication", match_fun = str_detect) %>%
mutate(Twitter = Twitter.y) %>%
select(-c(Twitter.x, Twitter.y))
saveRDS(directory_final, "directory_with_hyperlocals.RDS")